Modes
- Active/active
- Active/passive
Active/active
- Users and client application send requests to both datacenters
- After write on first DC, data need to be immediately visible for reading on second DC
- Default settings
- Worse performance
Active/passive
- Users and client application send requests to one datacenter
- Second DC used just as a backup in case of failure of first DC
- Better performance
Communication details
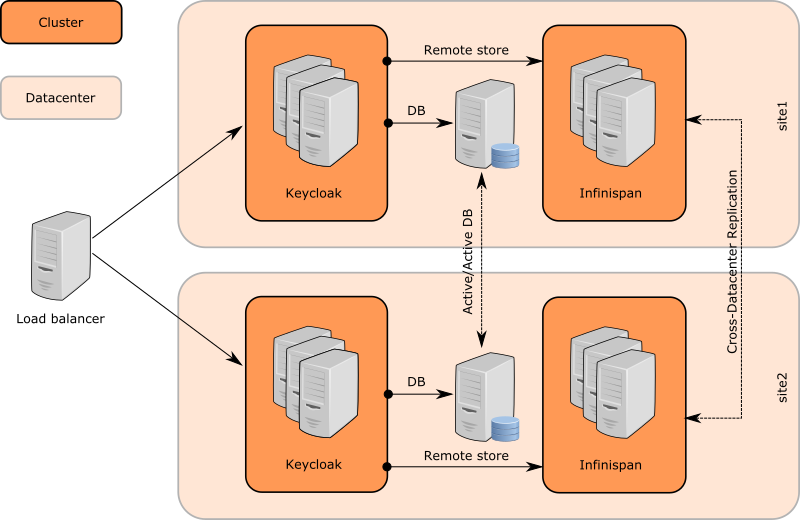
- 5 infinispan clusters with 2 datacenters setup
- Keycloak nodes cluster in site1
- JDG nodes cluster in site1
- Cluster between JDG nodes on site1 and on site2 (JGroups RELAY2 protocol and backup caches)
- JDG nodes cluster in site2
- Keycloak nodes cluster in site2
- Keycloak sends message to JDG server on same site
- JDG server sends it to JDG server in the other site through RELAY2
- JDG server on second site propagates it to Keycloak servers on second site through HotRod protocol (Client listeners)
- Keycloak servers listen to events through client listeners and do appropriate actions (Invalidate cache, update session caches)
- Communication between JDG servers from different sites through RELAY2 protocol.
- RELAY2 protocol - configured in JGroups subsystem on JDG server side
- Infinispan caches on JDG side - "backup" element
- Keycloak nodes and JDG nodes in same DC communicate through HotRod protocol
- Keycloak infinispan caches are configured with "remote-store" in standalone-ha.xml
- JDG server needs to have caches with same names configured on it's side
Basic setup
- Documentation: http://www.keycloak.org/docs/latest/server_installation/index.html#setup
- Recommended to try this to understand cross-dc better
Cross-DC deployment administration
Recommended startup order
- Replicated databases in both datacenters
- JDG servers in both datacenters
- Keycloak servers in both datacenters
Requirements
- Keycloak requires database in its DC to be running
- Keycloak requires (at least one) JDG server in its DC to be running
- Keycloak doesn't strictly need JDG server on the other DC to be running, but it's recommended
- If JDG server on other DC is not running, it means that second datacenter is "offline" from first datacenter PoV
Taking site offline
- Datacenter "site2" is considered offline from the "site1" PoV if:
- There are no running JDG servers in site2
- Network between site2 and site1 is broken
- "Take site offline" = make sure that site1 consider site2 as offline
- When site1 knows that site2 is offline, it will ignore it.
Manually taking site offline
- It's possible on JDG server side through JMX (jconsole) or through CLI
- Refer to JDG documentation for more details
- Site needs to be taken offline separately for every cache or at CacheManager level
Automatically taking site offline
- Done through the configuration on JDG side
- Element "take-offline" inside "backup" on caches
- With our default configuration, site is taken offline after it's unreachable for 60 seconds since first failed request
- On Keycloak side, user requests will be blocked for few minutes
- Exceptions in JDG server logs about failed backups
- Possible to decrease timeout by switch backup policy from FAIL to WARN
Taking site online
- Can be done once the network between sites is fixed and/or JDG servers on site2 started
- Needs to be done manually by admin
- JMX or CLI
- Other possible needed actions
- State transfer
- Clear Keycloak caches
State transfer
- Needs to be done manually
- Again through JMX or CLI on JDG server side
- Admin needs to decide if bidirectionally or unidirectionaly
- Some data may be lost/overwritten
Clearing caches on Keycloak side
- Needed if some KC entities were updated, but caches not invalidated during outage
- Can be done on single KC server on any site -- should propagate it to all others
Backup policy
- Configurable on JDG server side
- FAIL (default) or WARN
- FAIL will propagate backup failures to the caller (Keycloak server)
- Keycloak can then retry the operation
FAIL policy - advantages
- Consistency of data between sites
- Correct behaviour if there is concurrent update of the entity
- One of the update operations will fail and will be retried
- No lost update (write skew)
- Correct behaviour if there is shorter outage between sites (EG. few seconds)
- Because operations will be retried, there won't be lost update
WARN policy - advantages
- In case of real longer outage (split-brain), the caller won't be blocked for long time
- EG. With site outage, the user logins will be blocked just for 10-30 seconds. With FAIL, 1-3 minutes.
Conclusion
WARN is better if you don't need 100% consistency AND you expect often split-brains (offline sites)
SYNC or ASYNC backups?
- ASYNC is sufficient for Active/Passive mode for all caches
- ASYNC won't notify if backup to the second site failed
ASYNC for actionTokens cache?
- ASYNC useful if it's not strictly needed single-use ticket
- ASYNC doesn't guarantee the single-use of OAuth2 code, which is REQUIRED per specs
- ASYNC - better performance, but worse security
ASYNC for session caches?
- Sufficient if all user and client requests end on same DC
- Case if all frontend clients use javascript adapter
- Case if loadbalancer forwards requests based on location and apps are available on both sites too